Data quality is essential for accurate reporting, analytics, and decision-making. Inaccurate or inconsistent data can lead to wrong decisions, poor business outcomes, and a lack of trust in data-driven decisions. Idempotency is critical for maintaining data quality by ensuring that data processing is consistent and accurate.
In data engineering, idempotency refers to the property of an operation where it can be applied multiple times, but the result will remain the same as if it were applied once. In other words, if an idempotent operation is applied repeatedly to the same input, the output will be identical to the output of a single application of the operation.
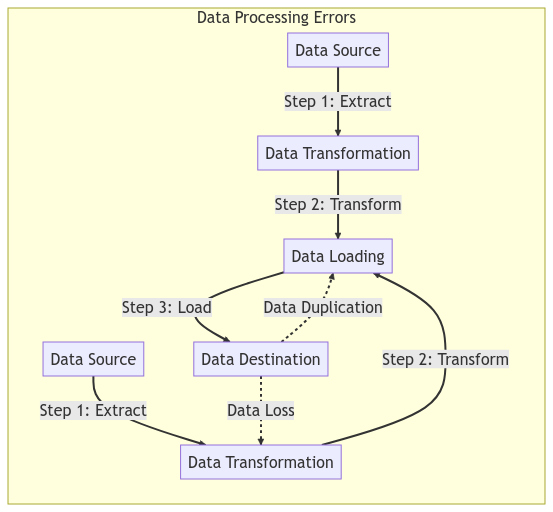
In the context of data pipelines, idempotency is crucial because it ensures that a pipeline can be re-run without introducing duplicate data or corrupting existing data. This is important because data pipelines can fail for various reasons such as hardware failure, network issues, or software bugs. Without idempotency, re-running a failed pipeline could cause data to be duplicated or lost, which can lead to data inconsistencies and errors.
By designing data pipelines with idempotency in mind, data engineers can ensure that their pipelines can handle failures gracefully and can be re-run safely without causing any data issues. This can lead to more reliable and robust data pipelines and ultimately improve the quality and accuracy of the data being processed.
Here are some examples of how idempotency ensures reproducible data quality in data engineering:
Preventing Data Duplication
Data pipelines often process large volumes of data, which can be challenging to keep track of. Without idempotency, the same data can be processed multiple times, leading to data duplication. This can result in inconsistencies in data processing and inaccurate reporting. With idempotency, data processing systems can identify duplicate data and ensure that it is not processed again.
For example, suppose you have a data pipeline that processes customer orders. If a customer places an order twice, without idempotency, the system could process the same order twice, resulting in duplicate data. With idempotency, the system can identify duplicate order and ensure that it is only processed once, maintaining data quality.
Preventing Data Loss
Data processing systems can encounter errors, such as network issues, server crashes, or software bugs. Without idempotency, these errors can result in data loss. With idempotency, data processing systems can be rerun with the same input, which produces the same output as the original run, and the system can continue from where it left off. This helps to avoid data loss and ensures that the processing is consistent.
For example, suppose you have a data pipeline that processes sensor data from IoT devices. If the data processing system encounters an error, without idempotency, it could lose data from the sensor. With idempotency, the system can be rerun with the same input, which ensures that the data is not lost and maintains data quality.
Promoting Consistent Data Processing
Inconsistent data processing can lead to inaccurate reporting and analytics. Idempotency ensures that data processing is consistent by producing the same output every time the operation is run with the same input. This helps to maintain data quality and trust in data-driven decisions.
For example, suppose you have a data pipeline that processes financial transactions. Inconsistent data processing can result in incorrect financial reporting, which can have significant business consequences. With idempotency, the system ensures that the processing is consistent, maintaining data quality and trust in financial reporting.
Benefits of idempotency for data quality
In summary, here’s a comparison table showing the benefits of idempotency for data quality:
| Prevents Data Duplication | Prevents Data Loss | Promotes Consistent Data Processing | |
| With Idempotency | Ensures that the same data is not processed multiple times, which prevents duplication and ensures data accuracy | Reruns the data processing with the same input in case of errors, which prevents data loss | Produces the same output every time the operation is run with the same input, which promotes consistent data processing and maintains data quality |
| Without Idempotency | Can process the same data multiple times, which can lead to duplication and inconsistencies in the data processing | Data processing errors can result in data loss, which can impact data quality and accuracy | Inconsistent data processing can lead to inaccurate reporting and analytics, which can affect business outcomes |
In conclusion, idempotency is critical for reproducible data quality in data engineering. It helps to prevent data duplication, data loss, and inconsistent data processing. By ensuring that data processing is consistent and accurate, idempotency helps to maintain the quality of the data, which is essential for accurate reporting, analytics, and decision-making. Implementing idempotency in data processing systems is crucial for maintaining data quality and trust in data-driven decisions.